The Perceptron Learning Algorithm (PLA) is one of the simplest Machine Learning (ML) algorithms. This post goes through an elementary example to illustrate how PLA works.
Notes on Perceptron Learning Algorithm
We start with some definitions and classification problem outline, next we move to the plain vanilla perceptron learning algorithm.
Linear Classifier
Consider set of points 





 = sign(W * x)")

 = 1")
")
, x_i \in X, i=1, \dots ,N\}")
is called the training data set.
Perceptron Learning Algorithm (PLA)
Given a training data set 


 = sign(W * x_i) = y_i")
The algorithm is iterative. On each iteration we will obtain new candidate value for 

=w_k * x")
Initialization. Assign 
Step 
- Compute values of
pairs on the training set until we find a misclassified pair, say, for
,
.
- Update the candidate using the rule:
.
Termination. Stop iterations when all points are correctly classified.
The intuition behind the update method (item 2) is that it adjusts ")
 = w_{k+1} * x_i")
*x_i")
 + y_i|x_i|^2")
and since always 
")

")
Example: One-dimensional Training Data Set.
The training data set consists of two training points:
, y_1 = -1")
, y_2 = 1")
also shown below:
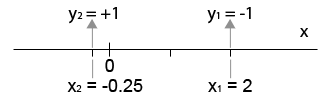
Figure 1. Training set. First coordinate of x is not shown (=1).
While this is probably the simplest example that can be devised to illustrate the PLA, it shows the idea behind it in a clear unobstructed way. By executing the PLA step-by-step we will first initialize ")
Iteration 1. We obtain:
 = sign(w_0 * x_1) = sign(0 * 1 + 0 * 2) = sign(0) = 1")
 = sign(w_0 * x_2) = sign(0 * 1 + 0 * ( - 0.25)) = sign(0) = 1")
Note that 


")
*(1, 2) = (-1, -2)")
Iteration 2. With the new candidate =w_1*x")
 = sign(w_0 * x_1) = sign( ( - 1) * 1 + ( - 2) * 2) = sign(-5) = -1")
 = sign(w_0 * x_2) = sign( ( - 1) * 1 + ( - 2) * ( - 0.25)) = sign(-0.5) = - 1")
As a side note, the decision boundary between the two classes is now located at 

Figure 2. Decision boundary after first iteration.
The value

 * 1 + ( - 2) * x = 0")
The misclassified point ")
 = (0, -2.25)")
That moves decision boundary to the root of the equation  = 0")

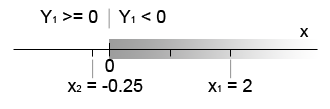
Figure 3. Second iteration moves decision boundary to x=0. Both training data points are classified correctly.
References
The PLA is covered by many books and articles. The AML Book listed below is easily accessible, well written and has a corresponding MOOC.
[1] Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin. “Learning From Data” AMLBook, 213 pages, 2012.

