Couple of 2d visualizations for Perceptron Learning Algorithm (PLA) are showing the behavior of plain vanilla PLA.
Animations
The following GIF animations illustrate the intuition behind the PLA: even though individual training samples may become incorrectly classified after single update, the decision boundary continues to converge to a classifier consistent with the training data.
Click on the thumbnails to see the corresponding GIF animation.
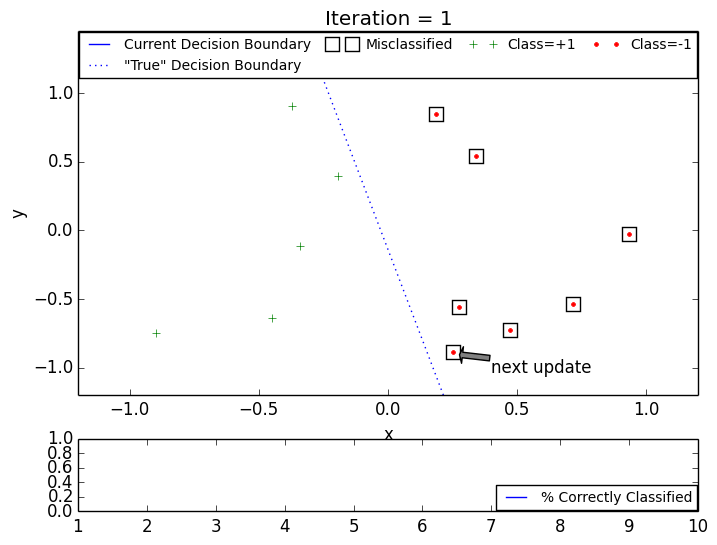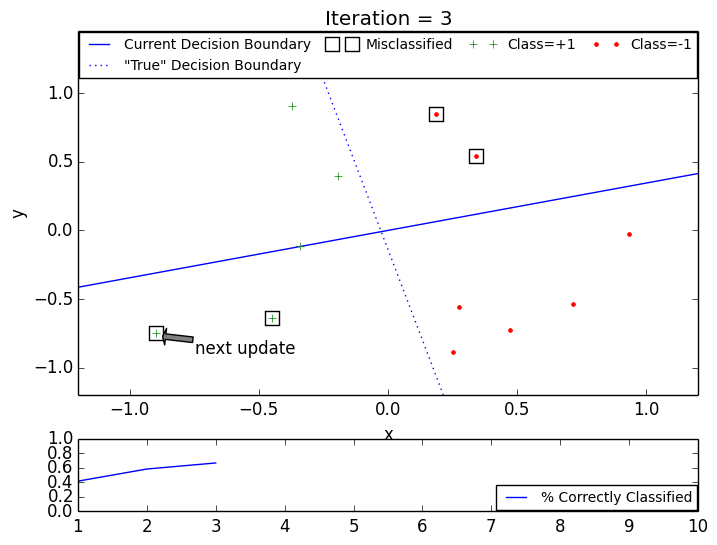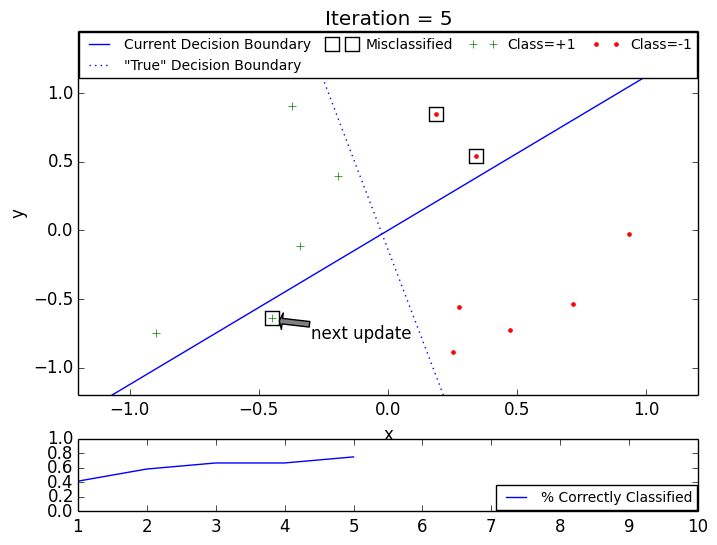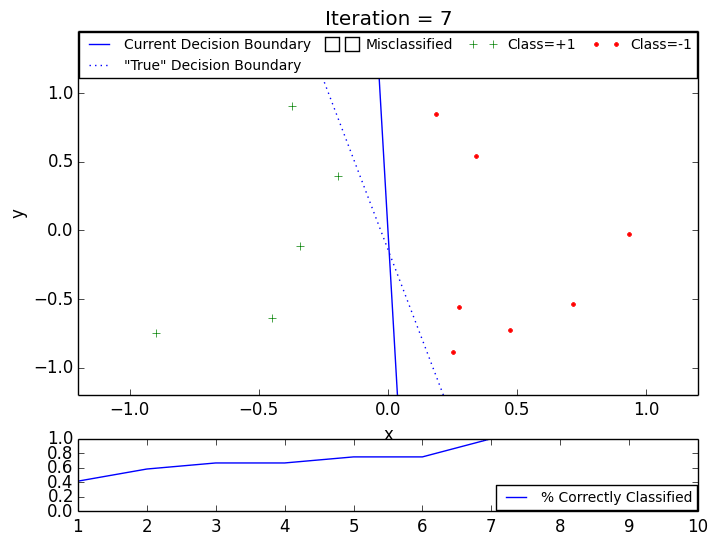
PLA: converged in 7 iterations, 12 training points.

PLA: converged in 38 iterations, 40 training points.
The third example shows that smaller separation margin for training samples results in much slower convergence at the end. It is interesting to note that the PLA classified most of the samples quite quickly and only three closest to the decision line were used to make fine adjustments for hundreds of iterations before the algorithms converged. This is expected for small margin cases and is reflected in PLA convergence theorem, which we hope to discuss in the next post.

PLA: narrow margin results in long convergence.
Python Snippets
The Python code for the PLA visualization is placed into a separate class, which either opens window with the next update or saves an image generated via pylab library. Since this code is essentially a straightforward extension of the visualization from the previous post, I decided not to include it in the post.
The PLA class is quite compact:
import numpy as np
import random
import linear_classifier
class PLA:
'''Basic (deterministic) implementation of Perceptron Learning Algorithm.'''
def __init__(self, training_data):
'''Stores training data and initializes linear
classifier with zero vector.
:param training_data: numpy array of training data.
'''
self.data = training_data
self.n_points = self.data.shape[0]
# Initialize classifier:
data_dim = self.data.shape[1]
vect_w = np.zeros(data_dim)
self.classifier = linear_classifier.Classifier(vect_w)
# Linear classifier, as initialized, classifies all as +1:
self.curr_classes = np.ones(self.n_points)
self.epoch_id = 0
self.progress = []
self.n_misclassified = 0
self.update_idx = None
self.update_error_measure()
def get_next_idx_to_update(self):
'''Basing on the current classes finds the first
index that needs and update (first mis-classified index).'''
self.update_idx = next(idx for idx, train, curr in
zip(range(self.n_points),
self.data[:,-1],
self.curr_classes)
if train != curr)
def compute_classes(self):
'''Computes current classes.'''
self.classifier.classes_of(self.data, self.curr_classes)
def update_classifier(self):
'''Updates classifier's decision vector.'''
delta_vect = self.data[self.update_idx, :-1]
update_sign = self.data[self.update_idx, -1]
self.classifier.vect_w[:-1] += update_sign * delta_vect
def update_error_measure(self):
'''Counts mis-classified samples and stores boolean array of
hits/misses, updates progress by recording percentage of the
correctly classified examples.'''
curr_class_equal = np.equal(self.data[:, -1],
self.curr_classes)
hits = np.sum(curr_class_equal)
self.n_misclassified = self.n_points - hits
self.progress.append(hits/float(self.n_points))
if self.n_misclassified == 0:
return
self.get_next_idx_to_update()
def next_epoch(self):
'''Performs one step in PLA. It applies current self.vect_w to
training samples to get their current classification,
saves "score", selects random mis-classified sample and
adjusts self.vect_w according to PLA rule.'''
self.epoch_id += 1
# No need to step is all samples are correctly classified
if self.n_misclassified == 0:
return False
self.update_classifier()
self.compute_classes()
self.update_error_measure()
return True
The function next_epoch() returns False when all points in training data are classified correctly. Until that we need to run a loop which is organized in a way to leave room for visualization to do its job:
pla = perceptron.PLA(training_data)
while True:
# Visualization calls come here.
if not pla.next_epoch():
break
A direct variation of the deterministic PLA selects next update index randomly among misclassified training samples:
def get_next_idx_to_update(self):
'''Instead of picking the first misclassified,
select a random misclassified one.'''
self.update_idx = random.choice([idx for idx, train, curr in
zip(range(self.n_points),
self.data[:,-1],
self.curr_classes)
if train != curr])
References
[1] Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin. “Learning From Data” AMLBook, 213 pages, 2012.

